Modular data availability for the OP Stack

Introduction
OP Stack has gained significant traction among rollup developers since its announcement last year. It is embraced by both developers creating new rollups and modular infrastructure providers like Caldera and Conduit, that enable developers to quickly launch their own rollups.
Modularity is a fundamental aspect of the OP Stack vision, as stated in last year's announcement:
Each layer of the OP Stack is described by a well-defined API, to be filled by a module for that layer. [...] Want to swap out Ethereum for Celestia as a data availability layer? Sure! Want to run Bitcoin as the execution layer? Why not!
Optimism’s fast-approaching Bedrock upgrade will modularize the OP Stack’s execution layers and proof system, enabling compatibility with future fraud and validity proofs.
Inspired by this, Celestia Labs has been focused on pushing the modularity of the OP Stack even further. And so today, we are pleased to announce the Beta release of a modular data availability (DA) interface for the OP Stack, the first OP Stack Mod that OP Labs is spotlighting for developer feedback. The interface allows developers to define a DA layer and inherit security from any blockchain they prefer, be it Ethereum, Celestia, or even Bitcoin.
Developers can start experimenting today with a version of the OP Stack that uses Celestia for DA and "settles" on Ethereum. And Caldera will soon release the Taro testnet, which allows developers and users to try out the first public testnet of OP Stack using Modular DA.
The data availability layer is the foundation of rollup architecture, ensuring availability of the data needed for independent validation of the rollup chain. Below we explore the basics of data availability in the OP Stack and how we’ve modularized it through a well-defined DA interface for publishing and retrieving data from L1.
This collaboration aims to inspire others to go modular and rethink blockchain architecture to the benefit of developers and users, advancing the industry into a collaborative era where modularism thrives over maximalism.
Data availability in the OP Stack: today
How does OP Stack handle data availability today? For our purposes, we dive into two fundamental components, the Rollup Node and the Batcher, as outlined below.
For a broader understanding of how the rest of OP Stack works under the hood, check out the Optimism docs.
Rollup node
The rollup node is the component responsible for deriving the correct L2 chain from L1 blocks (and their associated receipts). The rollup node retrieves L1 blocks, filters the transactions for data, often in the form of transaction calldata, and derives the correct L2 chain from this data.
Batcher
The batch submitter, also referred to as the batcher, is the entity submitting the L2 sequencer data to L1, to make it available for verifiers. Both the rollup node and the batcher work in a loop such that newly submitted L2 block data by the batcher is retrieved from the L1 by the rollup node and is used to derive the next L2 block.
Each transaction submitted by the batcher includes calldata which is the L2 sequencer data split into bytes called frames, the lowest level of abstraction for data in Optimism.
A modular DA interface for OP Stack
In creating a modular DA interface for OP Stack, our objective is simple: to enable rollup developers to specify any blockchain as their data availability layer, whether that’s Ethereum, Celestia, or even Bitcoin. In the absence of such an interface, each integration of a new DA layer could require developers to implement and maintain a separate fork of OP Stack.
OP Stack already includes abstractions which specify the L1Chain and L2Chain in the codebase, allowing us to model a new blockchain-agnostic interface for the Data Availability Chain, which we call the DAChain.
Using the interface defined below, it’s possible for developers to implement a DAChain to read and write data to any underlying blockchain or even a centralised backend like S3.
// We will re-use some terminology from op-node codebase
// Ref is a reference to some object, so FrameRef is a reference to a frame
// DAChain allows reading and writing data to the DA layer
// FrameRef contains data to lookup a frame by its reference
// Here it contains the block height and the tx index at which the transaction
// was included, the combination of which uniquely references the frame.
type FrameRef struct {
BlockHeight uint64
TxIndex int64
}
// Marshal / Unmarshal
func (f *FrameRef) MarshalBinary(w io.Writer) error { ... }
func (f *FrameRef) UnmarshalBinary(r ByteReader) error { ... }
// FrameFetcher returns a Frame from the DAChain by it's FrameRef
type FrameFetcher interface {
FetchFrame(ctx, ref FrameRef) ([]byte, error)
}
// FrameWriter writes a serialized Frame to the DAChain and returns its FrameRef
type FrameWriter interface {
WriteFrame(ctx, []byte) (FrameRef, error)
}
// DAChain satisifes both read/write on the DAChain
type DAChain interface {
FrameFetcher
FrameWriter
}Write phase
The following write example for Celestia implementation of the interface outlines integration with the batcher:
SimpleTxManager.send is the function responsible for creating and sending the actual transaction, it is modified to call WriteFrame which writes the frame to the Celestia and returns a reference.
The reference is then be submitted as calldata to the batch inbox address in place of the usual frame data.
// send performs the actual transaction creation and sending.
func (m *SimpleTxManager) send(ctx context.Context, candidate TxCandidate) (*types.Receipt, error) {
...
ref, err := m.daChain.WriteFrame(ctx, candidate.TxData)
...
err := ref.MarshalBinary(buf)
...
// Write ref to calldata
tx, err := m.craftTx(ctx, TxCandidate{TxData: buf, ...})
...
}
// WriteFrame writes frame to DA and returns its ref
func (c *CelestiaDA) WriteFrame(ctx context.Context, data []byte) (FrameRef, error) {
// Write frame to celestia
tx, err := c.client.SubmitPFB(ctx, nid, data, gas, fee)
...
return ref, nil
}Read phase
And here’s an outline of how a Celestia implementation of the interface integrated with the rollup node would look like:
DataFromEVMTransactions is the function responsible for returning the frame data from the list of transactions. It is modified to use the frame reference retrieved from the batch inbox calldata to actually fetch the frame and append it to the return data.
func DataFromEVMTransactions(config *rollup.Config, daChain *rollup.DAChain, batcherAddr common.Address, txs types.Transactions, log log.Logger) ([]eth.Data, error) {
...
// Read ref from calldata
err := buf.Write(tx.Data())
...
err := ref.UnmarshalBinary(buf)
...
data, err := daChain.FetchFrame(ctx, ref)
out = append(out, data)
...
}
// FrameFetcher returns a Frame from the DAChain by it's FrameRef
func (c *CelestiaDA) FetchFrame(ctx, ref FrameRef) ([]byte, error) {
...
// Read frame from celestia
data, err := c.client.NamespacedData(context.Background(), nid, ref.BlockHeight)
...
return data[ref.TxIndex], nil
}Note that the call to NamespacedData returns an array of byte slices of all the blobs submitted at the given BlockHeight, hence we return only the TxIndex we’re interested in.
Integrating Celestia as the DA layer
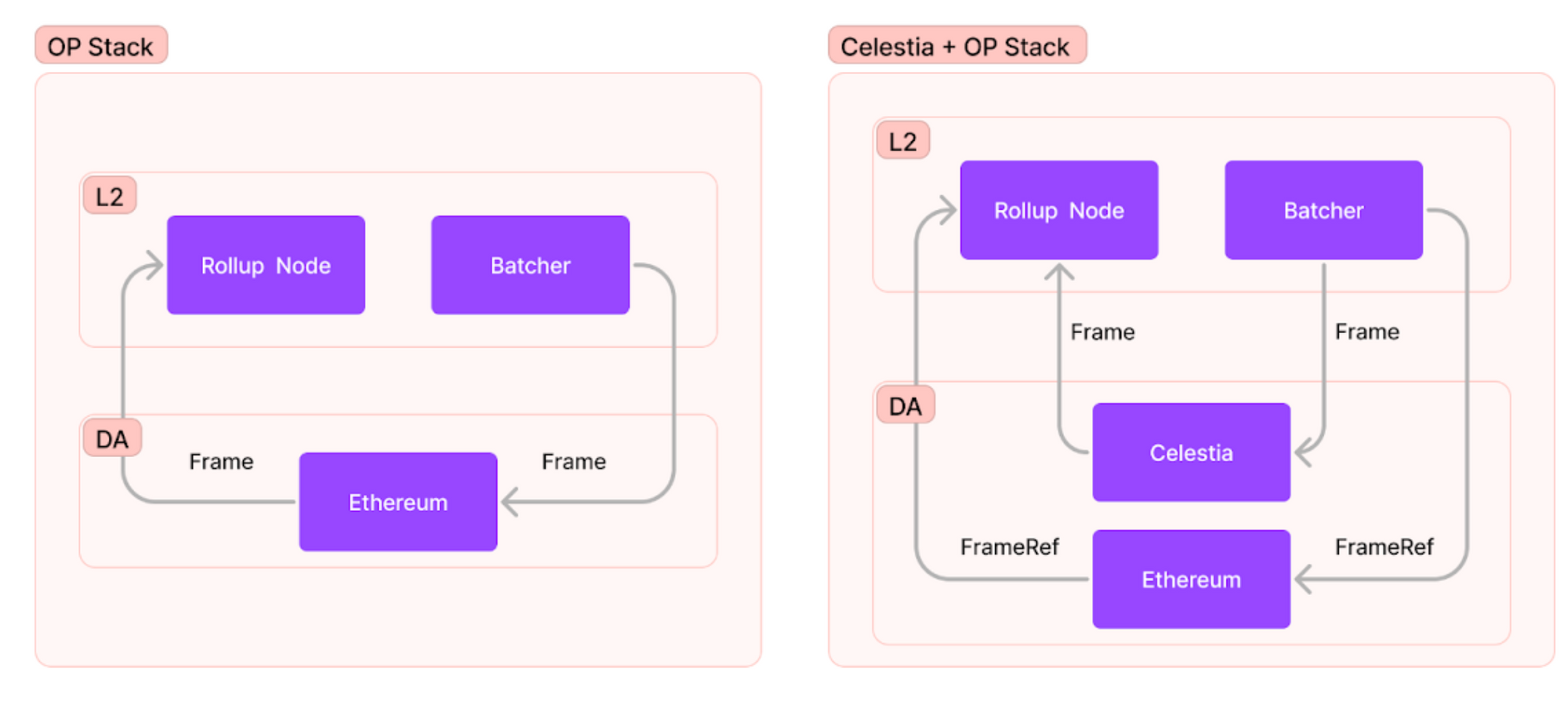
With a few minor modifications to the rollup node and the batcher, we can make the OP Stack use Celestia for DA.
This means that all the data that is required to derive the L2 chain can be made available on Celestia as native blob data instead of posting to Ethereum, although a small fixed-size frame reference is still posted to Ethereum as batcher calldata. The frame reference is used to look up the corresponding frame on Celestia using a celestia-node light node.
How does integration work?
Write phase
As described above, the batcher submits L2 sequencer data as bytes called frames to the batch inbox contract address on Ethereum L1.
We retain the batcher and the calldata transactions to guarantee ordering for the frames but we replace the frames in the calldata with a fixed size frame reference. What is a frame reference? It’s a reference to the Celestia data transaction which has successfully included the frame data as part of Celestia.
We do this by embedding a celestia-node light node in the batcher service. Whenever there is a new batch waiting to be submitted, we first submit a data transaction to Celestia using the light node, then submit only the frame reference in the batcher calldata.
Read phase
In the read phase we do the opposite i.e we use the frame reference from the batcher transaction calldata to resolve it and retrieve the corresponding actual frame data from Celestia. Here again, we embed a celestia-node light node in the rollup node to query it for transactions.
When deriving the L2 chain, the rollup node is now transparently reading the data off the light node, and is able to continue constructing new blocks. The light node only downloads data which was submitted by the rollup and not the entire chain as in the case of Ethereum.
Looking ahead
Fraud proofs are a key part of Optimism’s post-Bedrock roadmap, and we hope to explore an upgrade of our OP Stack x Celestia integration to work with fraud proofs on top of Ethereum Mainnet.
To do so, we can leverage the Quantum Gravity Bridge (QGB), which relays cross-chain DA attestations to Ethereum to enable onchain verification that a rollup’s data has been made available on Celestia, so that rollup data can be used and authenticated within a fraud proof. This will allow OP Stack rollups to tap directly into the DA guarantees provided by Celestia.