Why Blockchain Benchmarks Are Usually Deceiving


Every blockchain claims to allow more transactions per second (TPS) than its competitors. Chains advertise figures from tens of thousands TPS (live today) up to several million for yet-to-be-released systems. At Celestia, we're pretty much never able to reproduce chains’ headline numbers against real-world deployments - and many of our partners have had the same experience.
As Jeff Bezos says, "when the anecdotes and the data disagree, the anecdotes are usually right". In this article, we'll explain why blockchain benchmarks are so misleading.
Why Benchmarks Overstate Throughput
The primary reason benchmarks tend to be so misleading is because they run relatively short bursts of traffic. There's a big difference between a system that can accept a million transactions per second for a few minutes or hours and a system that can sustain that load indefinitely in production. Unless you run it for weeks, a benchmark can't show you your real capacity.
This is well understood among blockchain developers. Ethereum's average throughput is intentionally capped far below the burst processing capability of its nodes. So is Solana's. Same with Tempo, Base, Optimism, Arbitrum, and all the rest. All chains do this for roughly the same reason - a production deployment has constraints that prohibit running continuously at peak capacity.
Storage Requirements
One key constraint that's not captured in most benchmarks is storage capacity. A system of record needs to maintain more than just the active account state; transaction bodies, logs from onchain programs, and execution receipts must be stored somewhere. Most blockchains store this data in an embedded DB on-device - but at millions of TPS, on-device storage is completely unsustainable. Given 100 byte transactions and a million TPS, transaction history grows at about 8.5 TB per day. That rate is small enough that a few hours of benchmarking doesn’t run into problems - but a production deployment would be out of the question without a redesigned storage subsystem.
Indexers are even more susceptible to bloat. Indexers are the off-chain software which make it possible to search a chain's history by sender, receiver, token, etc. They're critical infrastructure for most chains - without them, users can't track their expenditures and apps can't track their usage.
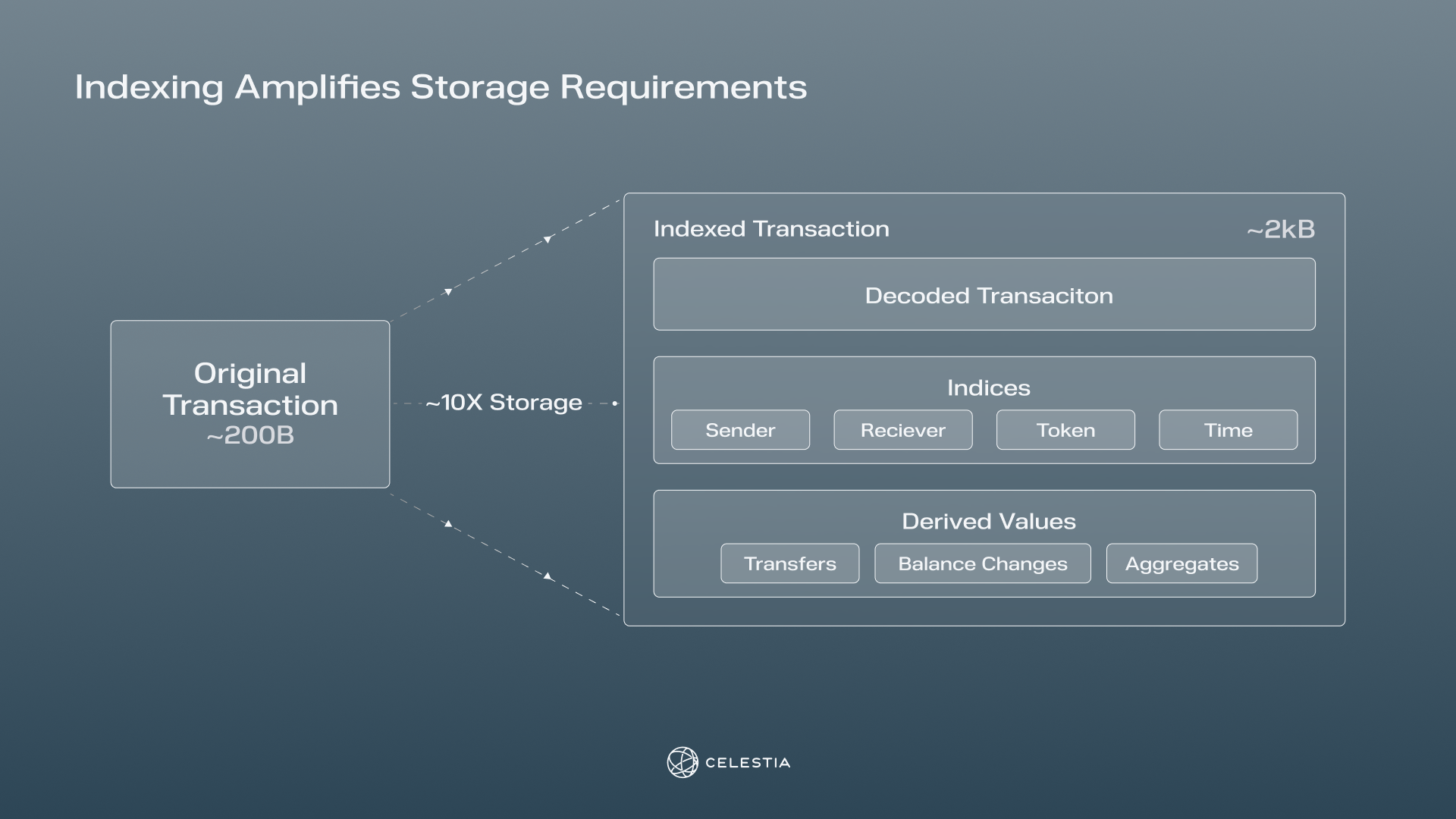
Indexing requires a lot of storage - up to ten times as much as the raw historical data. By far the most common strategy for indexing is to dump all of the chain data into a relational database. That works fine for chains that only do a few hundred TPS. But if you want to process millions, you need a storage backend that can handle petabytes of data and ingestion/query pipelines to match. Since most benchmarks don't include indexing, these problems are invisible from the headline numbers - but developers of high performance chains are acutely aware of them. In private conversations with developers, indexing is the single most commonly cited barrier to adoption of high performance chains.
Underestimating IOPS
A second systematic failure of benchmarking is in estimating IOPS. Blockchains need to persist their state somewhere, and they need fast access to that state when a user interacts with a cold account. To keep latency down, chains almost universally store their account state in an embedded DB. Every transaction modifies that state in several places, and all of those changes must ultimately get reflected on disk. That requires a lot of write throughput, even after batching and coalescing.
For write-bound workloads, RocksDB is the near-universal choice. Due to its append-only design, it provides excellent write latency and throughput. But that throughput comes at a cost - append-only designs suffer from significant storage amplification. To mitigate that problem, RocksDB relies on compaction - each time a "level" of the append-only log fills up, RocksDB iterates over the entire contents of that level and removes stale values. Then, it writes the deduped values into the larger, lower "next" level of the tree. When that level fills up, it too has to be compacted and written to an even lower level. This design means that compactions follow a pattern; the highest level has very cheap but frequent compactions (on the order of seconds). At the next level, compactions are several times more expensive but several times less frequent. At the low levels of the DB, compactions are rare (on the scale of hours or days), but very costly.
What this means in practice is that throughput drops significantly over the first few months of a chain's operation, then begins to level off as the DB size stops increasing. Short benchmarks can significantly understate IOPS, especially if the database is small or the developers loaded it from a pre-compacted snapshot.
Enabling Fast Sync
A third item that benchmarks don't reflect is the amount of time required to provision ("sync") a node. Low sync times are essential to overall chain health. If sync times are too long, it becomes nearly impossible for operators to replace failing hardware or adjust capacity.
When a node wants to join the network, it typically syncs in two steps. It starts by downloading a snapshot to bootstrap its view of state, and then it processes all of the remaining transactions until it has caught up to the chain tip.
Running the chain close to capacity increases sync times dramatically. The rest of the network keeps accepting new transactions while you’re syncing - which makes syncing like trying to catch up to a moving train.

The blowup is easiest to see with an example. Suppose a node syncs from a six hour old snapshot. If downloading and ingesting the snapshot takes about an hour, then the node will be seven hours behind the chain tip when it starts the catchup phase - and new transactions keep arriving while it syncs. If the chain is operating at 10% capacity, sync time is less than two hours: 1 hour to download the snapshot, 42 minutes to process the 7 hour backlog, and ~5 minutes to process the new transactions ingested in the interim. But if the chain is operating at 90% of its peak capacity, catching up will take over sixty hours!
Making Transactions Available
Another common pitfall is to ignore the process of disseminating transaction data. For a blockchain to be verifiable, it's crucial that anyone can download a complete record of what happened and check that the rules were followed. Making this record retrievable without a trusted intermediary is called providing Data Availability (DA). On most blockchains, DA is handled by peer-to-peer (p2p) broadcast. Every node downloads every transaction from its peers and serves it upon request.
Naive data availability does not scale. Since p2p broadcast is so unreliable, each node needs to disseminate the data to many peers simultaneously; otherwise, a few bad peers could stall propagation. This gives blockchains extraordinary bandwidth requirements. Ethereum processes ~640Kb of data per second and needs a 50Mb/s internet connection. Solana averages about 20Mb/sec and recommends a 10Gb/s link. Assuming 200 byte transactions, Solana’s bandwidth requirements could support a ceiling of ~12.5k TPS.
Scaling DA is extraordinarily difficult. DA faster than tens of megabytes per second only became tractable with the invention of specialized techniques like ZODA in the last few years. Using ZODA, the system behaves much more like a traditional cloud storage module. Because data is erasure coded before broadcast and each peer only maintains a small proportion of the total, capacity increases linearly with the number of peers. Celestia Fibre, which implements ZODA, can support up to 1Tb/s of DA or ~625M TPS, finally allowing blockchain applications to operate at Internet-scale.
Light at the End of the Tunnel
Blockchains operate far below their benchmarked capacity even when the benchmarks are well-designed because production deployments have constraints that benchmarks can’t capture.
Auxiliary systems like indexers need to keep up and stay in budget. The system has to keep running indefinitely, but storage performance degrades over time. And operational issues like syncing and block broadcast become increasingly important as the chain’s distribution grows.
Running the chain well below its benchmarked capacity is both the easiest and the most comprehensive fix - that’s why it’s so widely employed. But if you understand the problems involved, they can often be addressed upfront.
At Celestia, we’re working on next generation designs that can run much closer to their benchmarked capacity. If that sounds interesting to you, get in touch!